
What Are The Best Entity SEO tools ? When ChatGPT Sows Confusion

The detailed technical analysis of an AI response reveals the active fabrication of disinformation: 70% of inadequate responses recommended with disconcerting authority. A terrifying finding!
The refinement work on our brand review tool applied to LLMs, Waikay, brings out unexpected results. It perfectly illustrates the serious problems posed by using LLMs instead of search engines.
Indeed, search engines and LLMs do not function in the same way. Where the former deliver us a list of sources, in the form of URLs that should be consulted to form our own opinion, LLMs provide analytical syntheses of these same sources. The difference is enormous: one offers informational content to dissect and evaluate, while the other provides “ready-to-think” answers.
Our research illustrates, with a concrete example, the limits, biases, and problems inherent in using LLMs as search engines. A trend that is amplifying and should quickly become the norm, forcing us to remain vigilant.
Knowing what LLMs know about our brands and companies is one of the reasons that pushed us to create Waikay. We must acknowledge that this tool has bright days ahead.
Here’s what happened…
The Revealing Experiment about Entity Seo tool
We asked ChatGPT the following question: “What are the best SEO entity tools on the market?” fully convinced that we are one of, if not THE, best available today.
Here’s the response we got: A list of 10 tools presented with the confidence and algorithmic authority characteristic of an LLM: Ahrefs, Semrush, seoClarity, Yext, InLinks, Conductor, BrightEdge, SE Ranking, Semrush Company, WordLift.
Problem: Our experience in the SEO field and particularly on the complex subject of named entities made us react. We know the competition and we know that some of the displayed sites don’t offer named entity analysis.
Worse, it includes, under two different names, one and the same company. Two of the proposed sites are actually one!
But why did ChatGPT get lost in such an irrelevant response?
First observation, which will obviously be at the heart of our reflection: this list exists nowhere on the web. And for good reason, ChatGPT fabricated it entirely, synthesizing without measure its training data and online searches, both unfortunately biased. It adds to this a share of hallucinations.
This case reveals a recurring phenomenon where any question, technical or not, can generate erroneous recommendations presented with authority, and mislead users on all types of specialized subjects.
Technical Analysis: Real vs Fake Entity SEO Tools
To ensure the reality of the problem, we analyzed each site on this list edited by ChatGPT one by one to verify whether they really offered named entity detection or not.
The results, although expected, remain troubling. Only one-third of the responses are correct. Let’s first study the three correct results, among which we appear, but not in a very good position:
✅ The 3 truly dedicated tools (30%) for named entity extraction
InLinks – 5th position
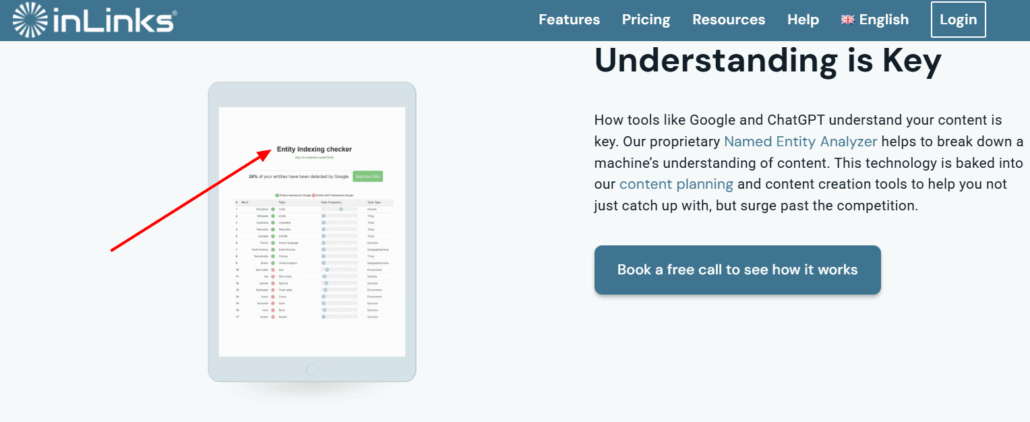
- Tool description: NLP algorithm that analyzes pages to automatically extract named entities and build a dedicated knowledge graph
- Functionality: Tool that submits a URL to see “which named entities have been detected by Google”
- Conclusion: InLinks is an integrated and automated entity SEO tool
Yext – 4th position
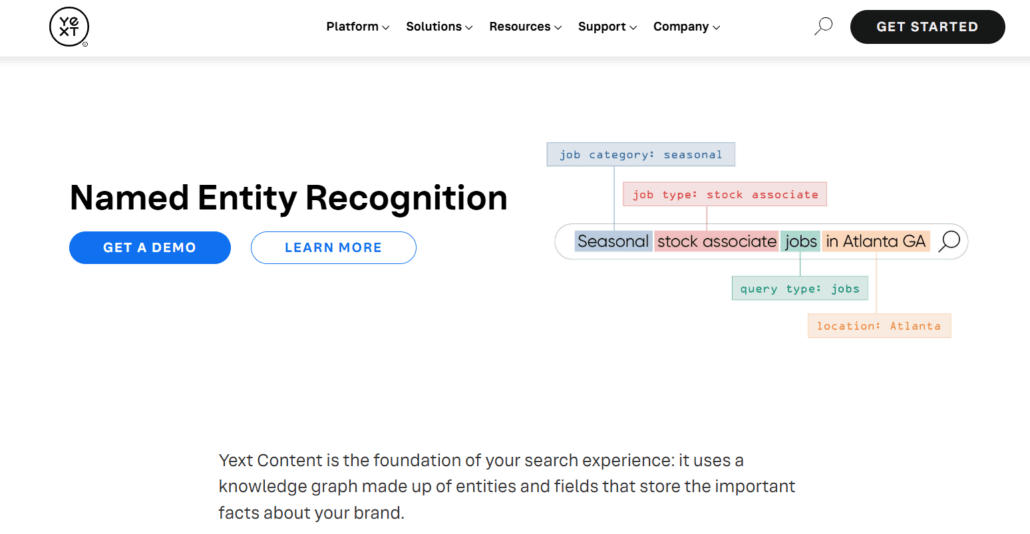
- Tool description: Integrated Named Entity Recognition (NER) that identifies words and classifies them into entity types
- Functionality: Customizable knowledge graph with flexible entities and complex relationships
- Conclusion: Yext is indeed an integrated and automated entity SEO tool
WordLift – 10th position
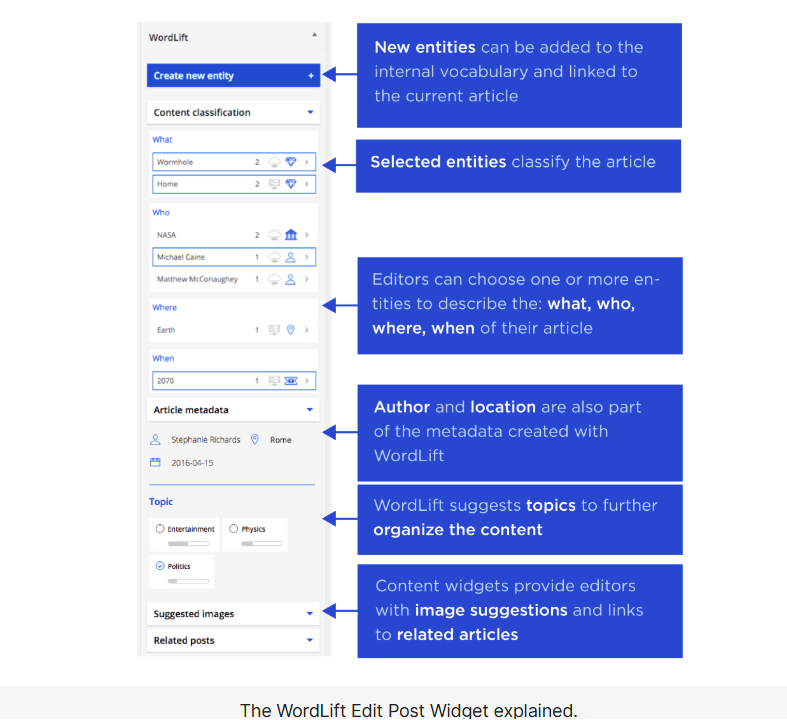
- Tool description: WordPress plugin specialized in entity linking and semantic SEO
- Functionality: Semi-automatic connection to Wikidata/Wikipedia databases, schema markup generation based on entities
- Conclusion: WordLift is a semi-automatic entity SEO tool
❌ The tool with ambiguous marketing (10%)
SeoClarity – 3rd position
The notion of “named entity,” however important it may be, remains misunderstood by many users, including professionals, who often confuse it with those of “keyword” and “topics.” An artistic blur that allows many semantic contortions, intentional or not…
This is what emerges, for example, from the analysis of this site, about topic research :

We note that although the term entity is mentioned, the list given by the analysis consists of keywords (taking into account plurals, spaces…).
- Tool description: Mentions “semantically related keywords, entities, and concepts” in its API
- Functionality: Offers “AI-driven entity groupings” but it’s essentially keyword clustering
- Problem: Ambiguous marketing that maintains confusion
- Conclusion: SeoClarity is not an entity SEO tool but a keyword research tool.
❌ The 6 completely inadequate tools (60%)
Finally, there are the sites that don’t claim to offer an entity analysis tool, and yet find themselves inserted in the list. The error comes from the LLM that attributed to them, wrongly, by hallucination or abusive extrapolation, this characteristic.
Ahrefs – 1st position
- Tool description: Excellence in backlink analysis, keyword research, technical audit
- Functionality: No named entity detection functionality
- Paradox: Their own glossary defines entity SEO but the tool doesn’t offer it
- Conclusion: Ahrefs is not an entity SEO tool.
Semrush – 2nd position
- Tool description: Complete SEO platform, basic semantic analysis, topic research
- Functionality: Does topic clustering, not true named entity detection
- Confusion: Marketing that mixes semantic analysis and entity recognition
- Conclusion: Semrush is not an entity SEO tool.
Conductor – 6th position
- Tool description: Content marketing and enterprise SEO platform
- Functionality: No specific named entity functionality identified
- Conclusion: Conductor is not an entity SEO tool.
BrightEdge – 7th position
- Tool description: Enterprise SEO platform with AI for content optimization
- Functionality: No specific entity recognition functionalities
- Conclusion: BrightEdge is not an entity SEO tool.
SE Ranking – 9th position
- Tool description: Rank tracking and basic SEO audit tool
- Functionality: No named entity functionality
- Conclusion: SE Ranking is not an entity SEO tool.
Semrush Company – 8th position
- Tool description: Apparent duplicate of Semrush (gross error in ChatGPT’s response)
- Status: Pure algorithmic error
- Conclusion: Semrush is not an entity SEO tool.
Why Does ChatGPT Produce So Many Errors about Entity SEO Tools ?
Once we’ve diagnosed the problems, it remains to define their causes. This work is difficult since it’s hindered by the opacity of the LLM’s operating modes. We can therefore only rely on hypotheses.
The Fundamental Confusion: Keyword vs Entity
Our analysis reveals the conceptual confusion at the heart of the problem: a keyword is not an entity. But this distinction is unfortunately not yet clear, even for many specialists…
In-depth Technical Definitions
Keyword : A keyword is a raw lexical character string extracted or identified in a textual corpus, without deep semantic contextualization. It’s a surface linguistic unit:
- Nature: Sequence of alphanumeric characters (“Apple”, “SEO”, “Paris”)
- Processing: Statistical, frequency, and syntactic analysis
- Context: Limited to the analyzed document/corpus
- Ambiguity: Polysemic by nature (Paris = city in France or Texas, first name, brand, etc.)
- Detection: Search by textual correspondence, basic indexing
- Granularity: Linguistic surface without disambiguation
Named Entity : A named entity is a disambiguated semantic unit representing a real-world object, with structured attributes and contextual relationships. The concept can be summarized as follows:
- Nature: Unique conceptual object with persistent identifier (URI, Knowledge Graph ID) that can most often be linked to a Wikipedia article
- Processing: Named Entity Recognition (NER) + Entity Linking + Knowledge Graph Integration
- Context: Enriched by relational metadata (geolocation, taxonomies, ontologies)
- Disambiguation: Resolved by schema markup (PERSON, ORGANIZATION, LOCATION) and distinctive attributes
- Detection: Semantic search, logical inference, contextual recommendations
- Granularity: Structured representation with properties and inter-entity relationships
Fundamental Distinction
| Aspect | Keyword | Named Entity |
|---|---|---|
| Representation | SRaw string | Structured semantic object |
| Identity | Ambiguous | Unique and disambiguated |
| Relations | Non-existent | Relationship graph |
| Evolution | Static | Dynamic (attribute updates) |
| AI Exploitation | Textual matching | Semantic reasoning |
Concrete Example:
- Keyword: “Apple” → simple 5-character string that can be a fruit, an electronics brand (Apple Inc.), a music production company (Apple Corps)…
- Entity: http://dbpedia.org/resource/Apple_Inc. with properties (Apple Inc.: founder: Steve Jobs, sector: technology, headquarters: Cupertino, CA, etc.) and relations to other entities in the knowledge graph
This distinction is crucial for modern AI and advanced semantic search.
If you’d like to find out more about keywords, entities and topics, here’s a complete article for you to read.
How Does ChatGPT Manufacture This Disinformation?
Here’s a modest attempt at explanation, personal and subjective…
Asumption #1: Original Pollution of Training Data
The problem starts upstream, in the data on which ChatGPT was trained and those it finds in direct web search. Thousands of generalist “Top SEO tools” articles have polluted the web for years, cheerfully mixing all categories of tools without always managing to distinguish them with acuity. These lists are often created by bloggers who prioritize publication speed over technical expertise, and include first the same popular platforms they know by name. Added to this are affiliation lists that deliberately favor tools offering the best commissions or the most accessible partner programs, without consideration for their specific technical relevance. This harmful bias is aggravated by generalized confusion in the content marketing industry between semantic SEO and entity SEO, two distinct concepts that many authors amalgamate through ignorance of technical nuances.
Asumption #2: Algorithmic Frequency Bias
ChatGPT’s algorithm seems to function partly on a statistical weighting principle: the more an element appears frequently in its training data, the more weight it has in its responses. Thus, Ahrefs and Semrush, which appear in about 90% of generalist SEO lists, acquire enormous algorithmic weight in the AI’s mind, regardless of their relevance for entity SEO. Conversely, InLinks, despite being a recognized specialist in entity SEO, appears less frequently in generalist web content and therefore finds itself under-represented in algorithmic calculations. This popularity/frequency logic makes the AI tend to privilege “mainstream” tools over real technical relevance, creating a vicious circle where marketing visibility takes precedence over specialized expertise.
Asumption#3: Algorithmic Synthesis Without Validation
Contrary to what one might think, ChatGPT doesn’t simply reproduce a pre-existing list found somewhere on the web. It operates a complex algorithmic synthesis, recomposing its own version by mixing the most frequently mentioned elements in its training data and online searches. This recomposition process is done without any technical verification of the actual capabilities of the mentioned tools. The algorithm has no mechanism to distinguish between marketing claims (what tools claim to do) and actual technical capabilities (what they really do). It simply aggregates the most frequent mentions and presents them as a coherent recommendation, thus creating a new form of algorithmic “truth” disconnected from technical reality.
Asumption #4: Hallucination by Logical Extrapolation
The most pernicious process is that of hallucination by extrapolation. The AI establishes seemingly sensible but technically false logical connections: “If Ahrefs is excellent for SEO and we’re talking about entity SEO, then Ahrefs must be good for entity SEO.” This flawed logic leads ChatGPT to create “truths” coherent in its thinking system but disconnected from technical reality. The algorithm thus invents capabilities or specializations that don’t exist, relying on idea associations rather than verifiable facts. All of this is then presented with artificial authority that completely masks the uncertainty of these extrapolations, giving the impression of expertise when it’s actually an approximate and largely questionable algorithmic construction.
The Damaging Consequences
For Specialized Brands (InLinks, WordLift, Yext)
Algorithmic Invisibility: The advanced technical solutions of these companies specialized in named entity extraction find themselves drowned in the noise of generalist AI recommendations.
Unfair Competition: These brands fight an unequal battle against the colossal marketing budgets of generalist platforms that saturate training data. While InLinks develops sophisticated semantic analysis functionalities, Ahrefs invests massively in content marketing, creating an artificial competitive advantage disconnected from technical value.
Expertise Dilution: Years of specialized R&D in knowledge graphs or entity extraction are reduced to a few generic lines in automated comparisons. This approximate algorithmic synthesis transforms precise technical innovations into interchangeable commodities, destroying the differentiation that justifies their existence.
For User Companies
Loss of Money: Companies subscribe to inadequate or non-existent tools, generating misplaced investments that cannot produce expected results.
Systemic Time Loss: Time lost using inadequate tools is not devoted to implementing truly adapted tools.
Technical Disillusionment: Companies might conclude too hastily that “entity SEO doesn’t work.” This disillusionment could create a global rejection of actually effective technologies, generating lasting skepticism toward valid technical approaches.
Dangerous Cognitive Dependence: The progressive delegation of technical decisions to unreliable algorithms creates an atrophy of critical judgment. Professionals could develop blind trust in systems whose functioning and limits they neither master nor understand. If it’s not already done…
For the Global Web Environment
Active Creation of Disinformation: LLMs risk eventually actively generating new forms of technical disinformation through algorithmic recombination, creating recommendations that never existed in original sources. The machine becomes a creator of false information rather than a simple amplifier of pre-existing errors.
Exponential Information Pollution: If taken at face value, each erroneous response from an LLM could influence thousands of decisions or content that would generate, in turn and in return, new decision-making or content based on these errors. This multiplication creates a snowball effect where error spreads exponentially, each cycle increasing the surface of informational contamination.
Forced Homogenization: AI could mechanically favor “popular” tools over-represented in its data, stifling specialized innovations that are less documented. This popularity logic creates a global impoverishment of technical innovation in favor of market uniformization.
The Necessity of Technical Fact-Checking
For professionals, it’s essential to systematically verify, even if it’s obviously difficult, the actual technical capabilities of tools before their adoption, as marketing promises don’t always reflect operational reality. This vigilance implies never taking AI recommendations as truth, given that these systems can reproduce and amplify errors present in their training data or on the web. Consequently, concrete functional tests should be privileged rather than blindly trusting marketing descriptions, which often tend to overestimate actual performance and minimize technical limitations of proposed solutions, through ignorance or for profit.
Conclusion: When AI Erects Its Own “Truths,” Where Do We Stand?
This small analysis of a ChatGPT response reveals a worrying phenomenon: the purely algorithmic creation of new false technical information.
The Finding is Edifying
70% of tools prove inadequate in a recommendation presented with authority. ChatGPT didn’t reproduce an existing error: it synthesized thousands of biased sources to create its own disinformation.
This active creation of algorithmic “truths” is more dangerous than simple error propagation because:
- It gives the illusion of expertise by aggregating approximations
- It creates artificial consensus where none exists among real experts
- It massively influences decisions without possibility of source traceability
- It puts companies with real expertise in competition with others that have… none.
The Civilizational Stakes
In a world where AI becomes a prescriber of technical solutions, we’re witnessing a silent transfer of recommendation power: from human experts (or pseudo-experts) to algorithms that manufacture their own “truths” without quality control.
Behind this innocuous list lies a major issue: who controls the creation of technical knowledge in the AI era? Algorithms or human expertise?
With this experiment, we have factual proof that AI can fabricate recommendations containing 70% error while presenting them with authority that discourages verification.
And your expertise, how is it perceived by LLMs?
You can verify it thoroughly with our Waikay tool: What AI Knows About You?